



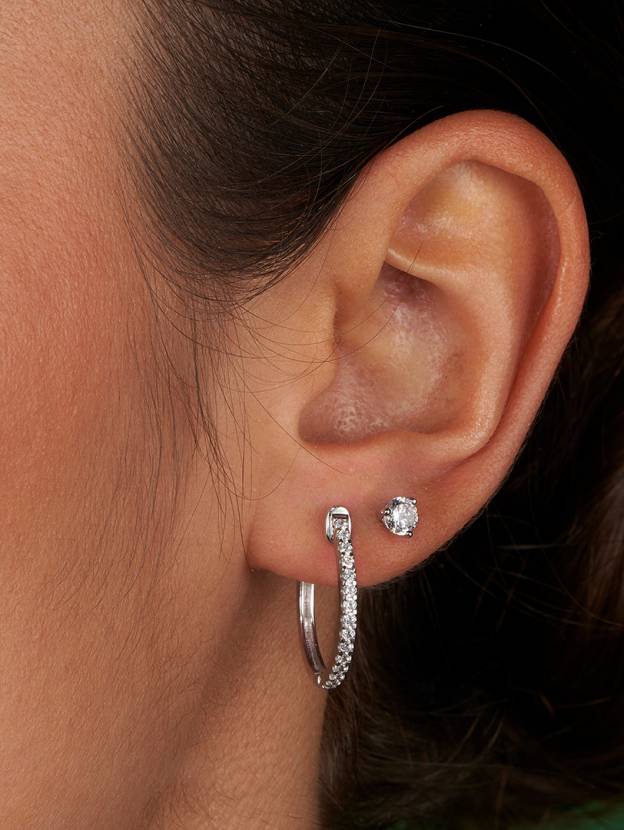

 Halo
Halo
 Cluster
Cluster


29
Nov
| Aspect | Recursion | Iteration |
|---|---|---|
| Memory Use | Stack grows with depth | Constant linear footprint |
| Convergence | Structural, mathematical convergence | Stepwise, predictable |
| Use Case | Tree traversal, recursive algorithms | Loops, streaming, hashing |
| Performance Risk | Stack overflow on deep calls | Less elegant for nested structures |
| Statistical Parallel | Sample → limit → stable output | Accumulate → finalize |





No account yet?
Create an Account